I en verden der forretningsprosesser støttes digitalt, og dermed setter sine spor i bedriftens IT-systemer, benytter process mining seg av disse sporene til å visualisere de reelle prosessene som forekommer.
Til forskjell fra tradisjonell business process management, hvor man setter opp og modellerer en ideell prosess, snur process mining dette på hodet, og bruker data fra bedriftens egne IT-systemer til å gi oss det faktiske bildet av prosessene våre – ikke den tenkte prosessen.
Process Mining hjelper deg å svare på spørsmål som: Hva skjer daglig i prosessene? Hvor er det avvik eller ineffektivitet? Oppstår det compliance hendelser? Hva er potensialet for forbedringer?
Hva får du med process mining?
For å forstå hva vi kan bruke process mining til må vi ta en titt på hva process mining tilbyr. Det er enklere for hjernen vår å forstå diagrammer og grafer som visualiserer store mengder data, fremfor å selv måtte strukturere og tolke en haug med prosesstegninger. Med ekte datadrevet prosessinnsikt får du:
- Full prosesstransparens: Fordi den visualiserte prosessen er basert på data fra bedriftens IT-systemer vil du få innsikt i alle steg av prosessen, og hvordan prosessen faktisk kjører.
- Prosessinnsikt: Når vi får alle steg av prosessen visualisert kan vi begynne å se hvor det er avvik i prosessen, hvor kostnadene ligger, og hvor det er stor ressursbruk eller hvor ledetiden bygger seg opp
- Agilt: Process mining er agilt – i stedet for å bruke måneder og store ressurser på visualisering av businessprosesser bruker du kun dager, og det uten å belaste organisasjonen
Vi arrangerer jevnlig kurs innenfor Business Intelligence. Sjekk ut vår kurskalender:

Hvordan kan vi bruke process mining til verdiskaping?
Process mining bygger bro mellom forretning og IT
Fordi prosessvisualiseringen er basert på faktiske data fra bedriftens IT-systemer, sikrer vi at vi alltid følger den faktiske, og ikke den tenkte prosessen. Det betyr også at så snart vi oppdaterer datagrunnlaget reflekteres det umiddelbart i prosessvisualiseringen. Det er dermed enklere å se hvor tett opp til idealprosessen man i realiteten er, og både forretningssiden og IT-siden kan sammen jobbe mot optimalisering og kontinuerlig forbedring av prosessen.
Hva trenger man for å drive process mining?
Det er kanskje lett å tro at for å drive med process mining må man ha et datavarehus og årevis med datahistorikk for å få noe fornuftig ut av det. I realiteten er det egentlig ikke så mye som skal til for å komme igang med process mining. Du trenger en eventlog, og denne loggen må inneholde noen viktige datafelter:
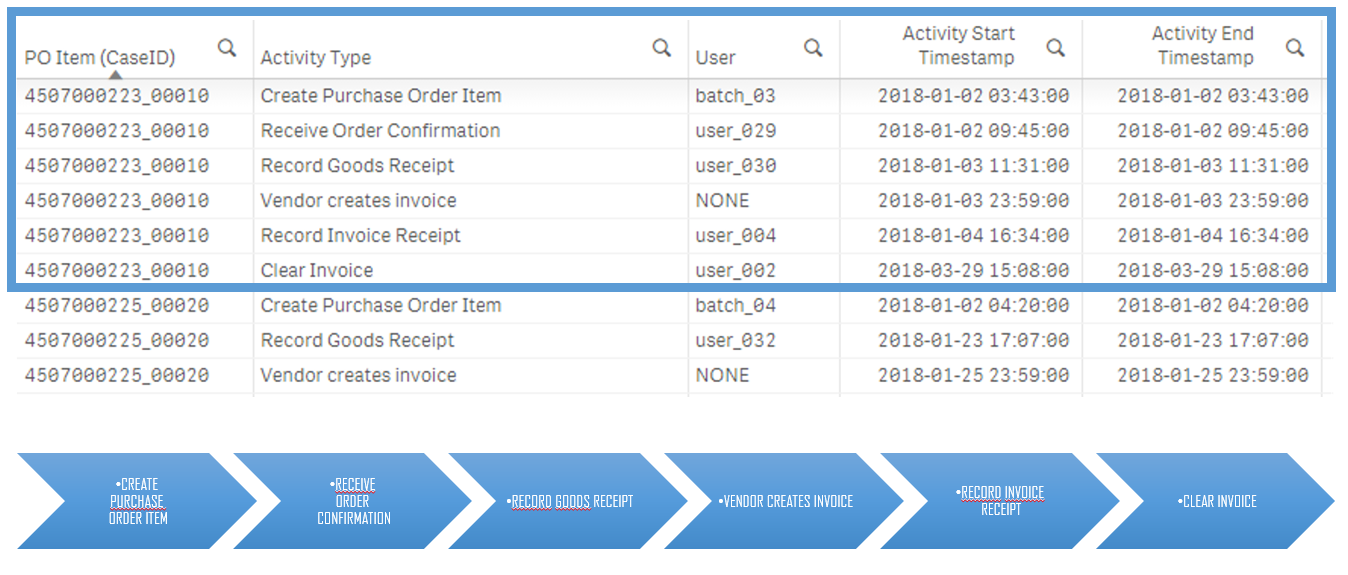
- ID-felt: Du behøver en unik identifikator for hver av instansen av et prosessløp. Dette kan for eksempel være et saksnummer for saksbehandlingsprosesser, et ordrenummer ved kjøp eller salg av varer, eller et materialnummer i en produksjonsprosess.
- Aktivitetstype: For hver instans av en prosess må vi kunne følge hvilke steg prosessen går gjennom. Dette feltet kan være en tekstlig beskrivelse av steget, som for eksempel “ordrebekreftelse sendt til kunde”.
- Bruker/ansvarlig: Det kan være smart å ha en oversikt over hvem som har vært ansvarlig eller utført de ulike stegene i prosessen. Dersom deler av prosessen er automatisert vil man kunne beregne automasjonsgraden av prosessen, og man får innsikt i hvilke steg som utføres manuelt, og kanskje er kandidater for automasjon.
- Systemtid for aktivitetstart og -slutt: For å kunne beregne ledetid for prosessen, samt hvor lang tid som brukes på hvert steg, må vi vite når hvert steg begynte og ble avsluttet. På den måten kan vi se hvor flaskehalsene oppstår i prosessen, og vurdere om vi skal automatisere eller sette inn flere ressurser på strategiske steder for å ta ned ledetiden.
Når vi har disse dataene på plass kan vi gå igang med process mining. Med datadreven prosessvisualisering vil du få innsikt i en rekke aspekter ved prosessen:
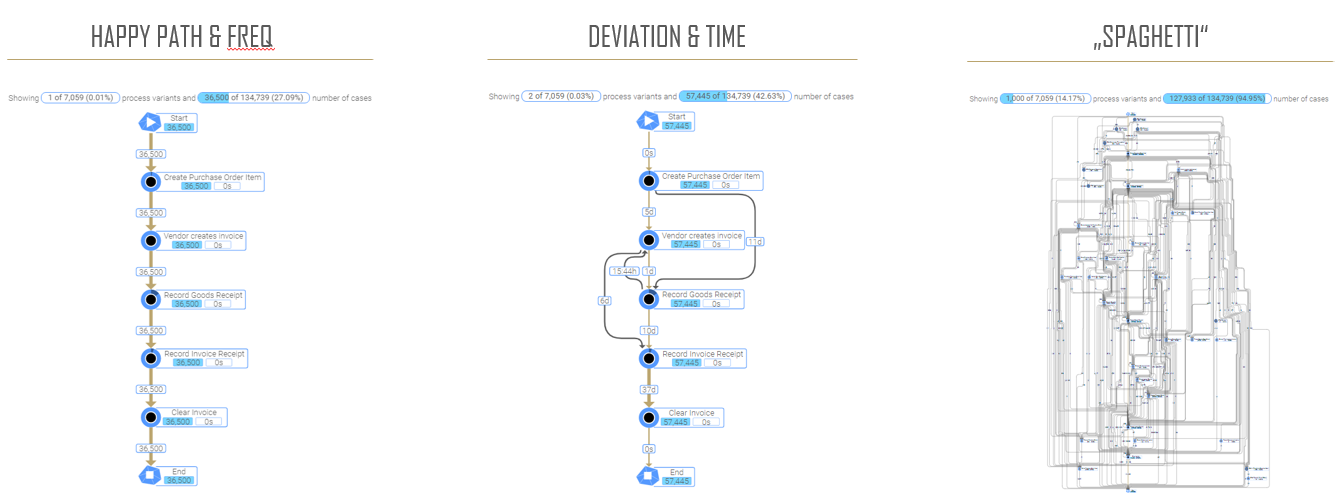
- Happy path og frekvens av forekomst: Visualiseringen viser oss det vanligste prosessløpet, såkalt happy path, og tilbyr støtte for å vise topp N prosessløp basert på hvor ofte de forekommer i datasettet.
- Avvik og tidsbruk: Vi får innsikt i prosessløp som avviker fra det vanligste prosessløpet, og har mulighet til å se tidsbruk og antall forekomster av avvik, enten som et antall eller som andel av totalen.
- “Spaghettien”: Visualiseringen gir informasjon om totalt antall variasjoner av prosessen, og gir oversikt over alle prosessløp som forekommer i datasettet.