
Denne omfattende løsningen integreres sømløst i Microsoft-økosystemet og tilbyr et enhetlig miljø der brukerne kan dra nytte av kraften til data og skyens skalerbarhet uten å bekymre seg for den infrastrukturen som trengs for å utføre store datatilpasninger. Selv om løsningens generelle tilgjengelighet ble kunngjort for bare noen måneder siden (15. november), har vi hos twoday allerede benyttet oss av denne lovende teknologien hos noen av våre kunder, selv mens den var i forhåndsvisning.
I dette blogginnlegget vil vi utforske de viktigste funksjonene som gjør Microsoft Fabric til en game-changer i en verden av skybasert dataprosessering.
En alt-i-ett AI-drevet analyseplattform
I utgangspunktet fungerer Microsoft Fabric som en plattform for online-dataprosessering designet for å håndtere en rekke forskjellige datarelaterte oppgaver. Fra dataengineering til analyse og maskinlæring gir den et enhetlig sted for dataeksperter å arbeide effektivt og samarbeide.
Business intelligence
En av de mest fremtredende funksjonene i Microsoft Fabric er en sømløs integrasjon med Power BI. Denne synergien sikrer en jevn overgang fra dataprosessering til visualisering og gjør det mulig for brukere å hente meningsfulle innsikter fra dataene sine. Plattformens evne til å lese direkte fra Lakehouse Delta-tabeller eliminerer behovet for å integrere datalagringen din med forretningsklare data i Power BI, da det er innebygd i Fabric. Denne integrasjonen strømlinjeformer rapporteringsprosessen og gir en sammenhengende helhetlig løsning.
Lagring
Microsoft Fabric leveres med en innebygd datalake kalt OneLake. Som navnet antyder er det en enkelt lagring innenfor ditt Fabric-miljø der du kan laste opp dataene dine, behandle dem og lagre dem i ønskede formater, for eksempel som Delta-tabeller i ditt Lakehouse. OneLake er bygget på ADLS (Azure Data Lake Storage) Gen2. Tanken bak dette er å ha en kopi av dataene over hele organisasjonen din for å unngå unødvendig duplisering og flytting. OneLake muliggjør også rask henting av data klar for rapportering til Power BI. Dette sikrer at brukerne kan få tilgang til den informasjonen de trenger i sanntid og tar dermed raske og informerte beslutninger.
Dataengineering
Når vi ser på noen av de andre funksjonene som Fabric tilbyr, nøler den ikke med å håndtere stordataprosessering. Med integrasjonen av Apache Spark kan brukerne dra nytte av kraften til distribuert databehandling for å effektivt behandle store mengder data. Med forskjellige kapasitetsalternativer kan du velge den beste databehandlingsinnstillingen for eksisterende arbeidsbelastninger og skalere opp eller ned etter behov. Enten det er i notatbøker eller som en del av Spark-jobbdefinisjoner, gir plattformen fleksibilitet til å håndtere utfordringer med store mengder data.
Orkestrering
Når det gjelder å orkestrere dine dataengineering-arbeidsbelastninger, utmerker Microsoft Fabric seg ved å tilby en innebygd Data Factory, som gir brukerne muligheten til å opprette datapipeliner og strømmer sømløst. For de som er kjent med den opprinnelige versjonen av Azure Data Factory, bør overgangen til å opprette og orkestrere rørledninger i Fabric være enkel.
Ettersom Microsoft streber etter å ha en enhetlig plattform der forskjellige dataperspektiver kan samarbeide, er det forskjellige "opplevelser" tilgjengelige for forskjellige dataspesialister. La oss se på noen av opplevelsene som er tilgjengelige i Fabric.

Figur 1: Det delte SaaS-grunnlaget for Microsoft Fabric.
Data Factory-opplevelse
I Data Factory-opplevelsen kan vi opprette datapipeliner på nesten identisk måte som i Azure Data Factory. Vi har våre Lookup, CopyData, ForEach og andre aktiviteter som fungerer på samme måte. Et eksempel på en rørledning som itererer gjennom visse konfigurasjonsparametere hentet av en notebook.
-1.webp?width=1235&height=274&name=MicrosoftTeams-image%20(22)-1.webp)
Figur 2: En pipeline som bruker en notatbokaktivitet for å returnere noen parametere for ulike enheter og deretter itererer med hver sett med parametere individuelt.
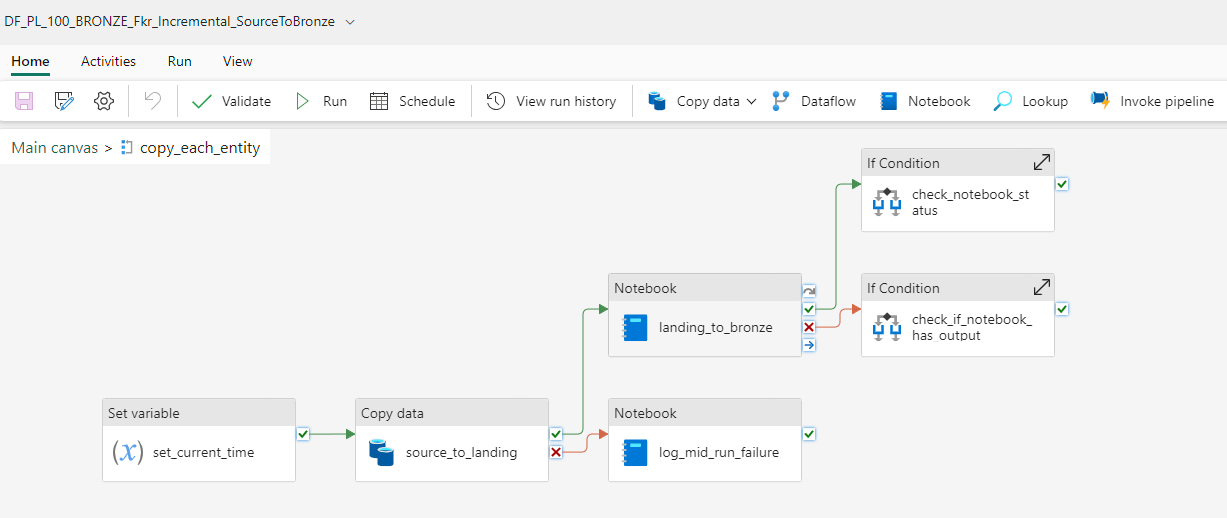
Figur 3: Logikk inne i ForEach-aktiviteten som kopierer data fra kildesystemet, lander det i landingssonen, bearbeider den landede filen og logger suksess/feil av ulike stadier ved hjelp av de overførte parameterne.
Data Engineering-opplevelse
Som nevnt tidligere er notebooks utstyrt med Apache Spark, en av funksjonene som følger med Microsoft Fabric. I det tidligere eksemplet kan vi se hvordan de kan brukes i våre datapipeliner, og siden det er mulig å skrive tilpasset kode i dem med forskjellige språk (Python, Scala, R, SQL), gir det utviklerne stor fleksibilitet til å oppnå det ønskede målet.
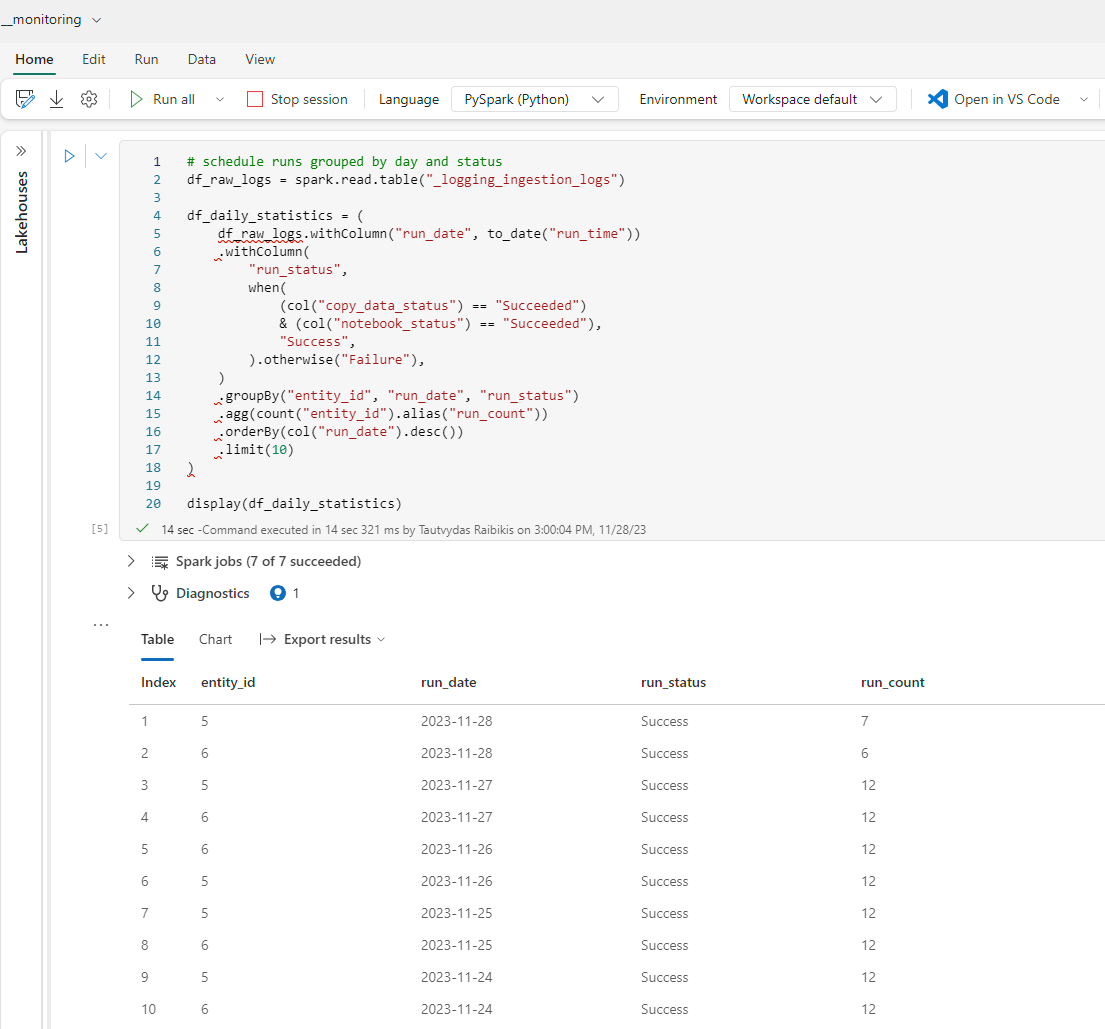
Figur 4: Eksempel på å kjøre PySpark-kode for å spørre en logg-tabell og få oppsummert daglig inntaksstatistikk.
Data Warehouse-opplevelse
Synapse Data Warehouse er et «tradisjonelt» datalager som støtter fullstendige transaksjonelle T-SQL-funksjoner som et bedriftsdatavarehus. Brukere av Fabrics lager har full kontroll over å opprette tabeller, laste, transformere og spørre data i datavarehuset med enten Microsoft Fabric-portalen eller T-SQL-kommandoer. Lageret har fullstendig transaksjonell DDL- og DML-støtte og opprettes av en kunde.
Et lager fylles av en av de støttede metodene for datainntak som COPY INTO-kommandoen, Pipelines, Dataflows eller tverrdatabase-inntaksalternativer som CREATE TABLE AS SELECT (CTAS), INSERT… SELECT eller SELECT INTO. Likheter med tradisjonelle datalagre gjør det enkelt for dataspesialister å tilpasse sin eksisterende kunnskap samtidig som de drar nytte av fordelene og skalerbarheten som Fabric tilbyr.
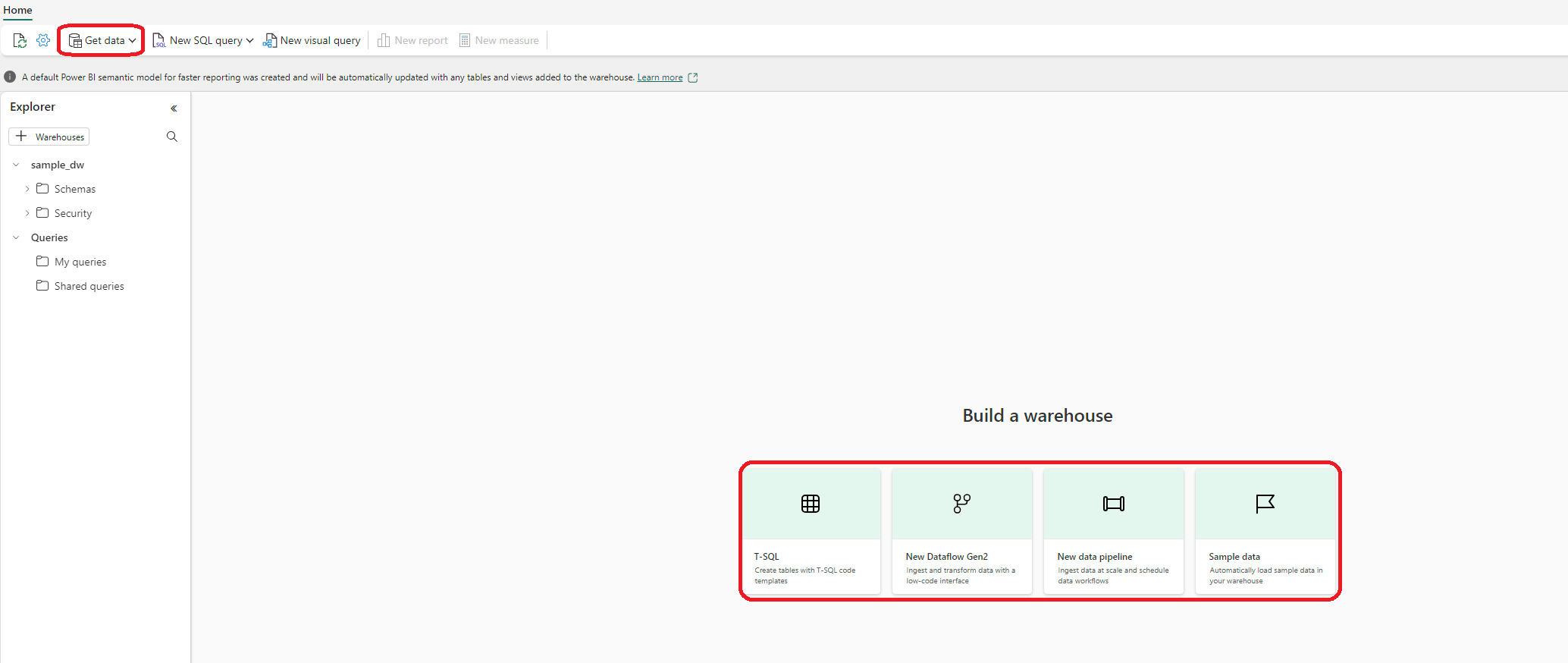
Figur 5: Metoder for å opprette objekter i Fabrics Data Warehouse-opplevelsen.
Data Science-opplevelse
Data Science-brukere i Microsoft Fabric jobber på samme plattform som forretningsbrukere, analytikere og ingeniører. Datadeling og samarbeid blir enklere over forskjellige roller som et resultat. Analytikere kan enkelt dele Power BI-rapporter og data, ingeniører kan hjelpe til med å undersøke problemer som kan oppstå fra kilden, og alt dette er lett tilgjengelig for data science-brukere. Enkelheten med å samarbeide over roller i Microsoft Fabric gjør kunnskapsoverføring og feilsøking mye enklere for alle.
Med verktøy som PySpark/Python, SparklyR/R kan notisbøker håndtere opplæring av maskinlæringsmodeller. ML-algoritmer og biblioteker kan hjelpe til med å trene maskinlæringsmodeller. Bibliotekshåndteringstjenester kan installere disse bibliotekene og algoritmene. Brukerne har derfor muligheten til å dra nytte av et stort antall populære maskinlæringsbiblioteker for å fullføre sin ML-modelltrening i Microsoft Fabric.
Dessuten kan populære biblioteker som Scikit Learn også utvikle modeller. MLflow-eksperimenter og kjøringer kan spore treningen av ML-modellen. Microsoft Fabric tilbyr en innebygd MLflow-opplevelse der brukere kan samhandle for å logge eksperimenter og modeller.
Konklusjon
Microsoft Fabric fremstår som en allsidig og kraftig løsning for organisasjoner som sliter med forskjellige datarelaterte oppgaver. Fra ustrukturerte til strukturerte data, fra dataengineering til analyse og maskinlæring gjør plattformens sømløse integrasjon med Power BI, innebygd datalake, T-SQL-støtte for datalagerarbeidsbelastninger, Data Factory og Apache Sparks funksjoner det til et omfattende verktøy for dataprofesjonen. Mens bedrifter fortsetter å navigere gjennom kompleksitetene i datalandskapet, skiller Microsoft Fabric seg ut som en enhetlig plattform som låser opp hele potensialet til data for informert og datadrevet beslutningstaking.
Vil du vite mer om Microsoft Fabric? Kontakt oss i dag