/To%20menn%20st%C3%A5r%20utenf%C3%B8rs%20og%20prater%20med%20hverandre.jpg?width=1280&height=1000&name=To%20menn%20st%C3%A5r%20utenf%C3%B8rs%20og%20prater%20med%20hverandre.jpg)
1. Mini-Norge:
Det har blitt opprettet et Mini-Norge. En basispopulasjon som er tilgjengelig og “levende” i syntetiske miljøer. De maskinlærte modellene genererer syntetiske testdata med de samme egenskapene som det opprinnelige datasettet.
For å lage Mini-Norge tok man 100.000 personer og innvandret inn i løsningen, og slik lage en statistisk representativ befolkning. Disse fikk norsk statsborgerskap, nye bosteder, og vi opprettet blant annet person-relasjoner, arbeidsgiver- og arbeids-historikk. Alt dette er data som er viktig for NAV for å utbetale ytelser og behandle de søknadene NAV får. For at Mini-Norge skal være relevant for testerne gjøres det endringer i systemet hver dag via en orkestrator, slik at dataen blir så representativt likt NAVs løsninger som mulig. Ved å for eksempel syntetisere fødsler og skilsmisser gjøres miljøet relevant for testerne av feks Foreldrepengeløsningen..
Nå har Mini-Norge vokst og det er oppe i 150.000 syntetiske personer i løsningen.
2. Dolly
Dette er en selvbetjeningsløsning som demokratiserer hvordan NAV lager syntetiske testdata. Løsningen gjør at alle kan opprette og skreddersy syntetiske data etter deres behov, ved å legge inn ulike egenskaper. For eksempel dersom man ønsker å teste en uvanlig situasjon kan du opprette testdata for denne situasjonen og så kjøre test på dette. Eksempelvis trenger Foreldrepengeprosjektet å teste hva som skjer når tvillinger er født i to forskjellige år, på hver sin side av nyttårsaften. Testdata for dette kan enkelt opprettes i Dolly. Man kan også opprette grupper på de testdataene man legger inn.
/NAV%20Mini-Norge.jpg?width=1280&height=1465&name=NAV%20Mini-Norge.jpg)
Syntetisering basert på maskinlæring
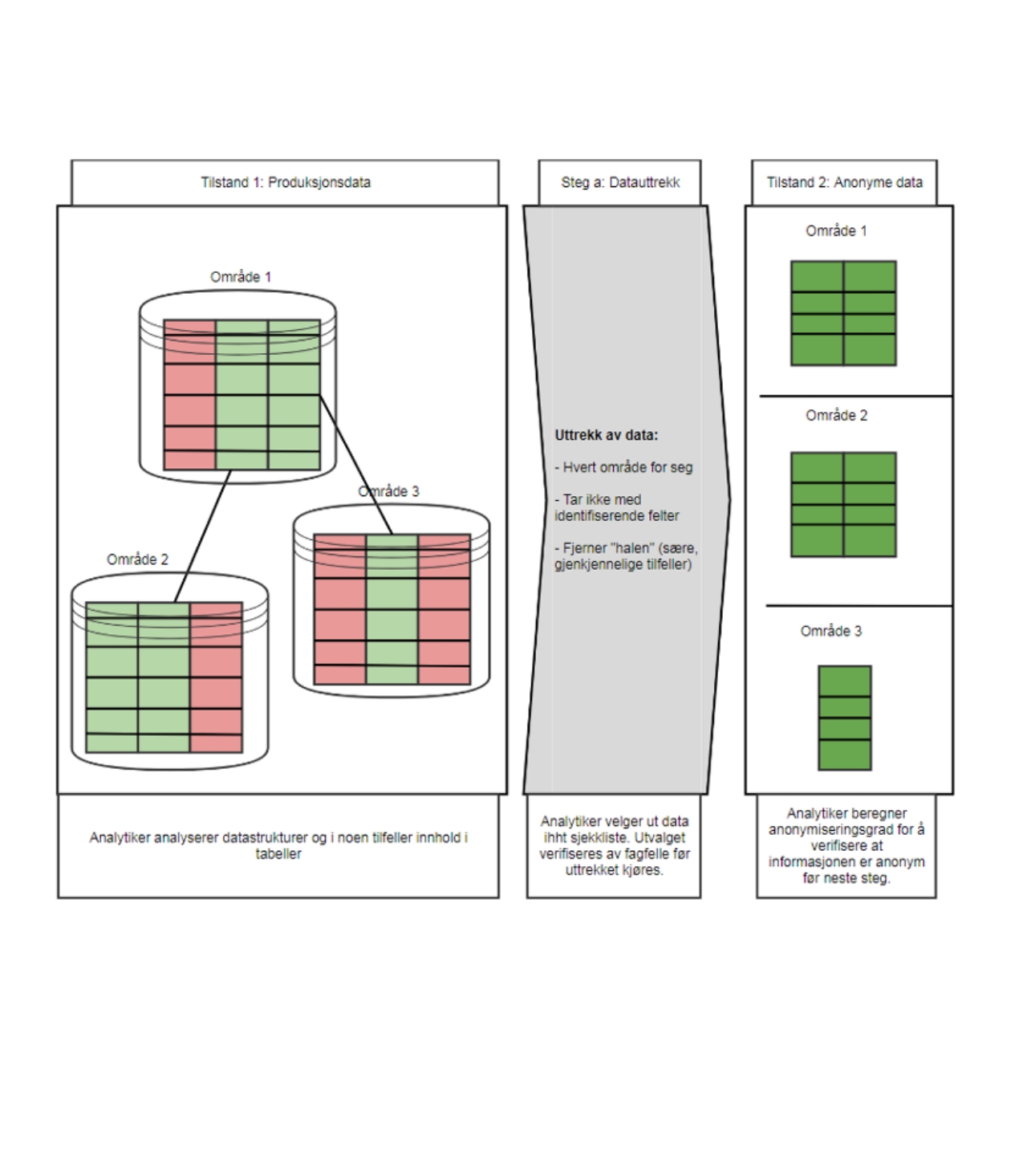
Tilstand 1: Vi har masse rå produksjonsdata som er mer eller mindre tilgjengelig, som vi gjør en analyseprosess på. Dersom det trengs kan vi gå inn å se på alle dataene, men ofte trenger vi kun å se på databasestrukturen og hvordan det ser ut.
Vi gjør så et uttrekk av de dataene, der vi stripper de for all direkte identifiserende informasjon og kapper halene på distribusjonene. Så det vi sitter igjen med er en anonym samling med data.
Tilstand 2: Denne samlingen med data går da til tilstand to. Her blir de kvernet på en maskinlæringsløsning for å kunne ta steget videre til tilstand 3. En typisk algoritme her er et beslutningstre (Decision Tree) som ligger i bunn og bestemmer hvordan datastrukturen skal se ut. Decision Tree er den algoritmen vi har brukt mest, men vi bruker også Synthpop, BeAn, PerlinNoise, CHAR-RNN, Random Forest.
Tilstand 3: Her blir dataene til frittstående syntetiske data som vi nå knar sammen igjen. Vi må tillegge dataene en fiktiv person, fordi det ikke er hensiktsmessig å ha en rekke hendelser dersom de ikke er knyttet til folk. Vi spør da Orkestratoren om å få et fødselsnummer og et navn.
Tilstand 4: Når vi så har satt sammen disse dataene igjen så dytter vi det inn i de registrene der det var meningen de skulle i utgangspunktet. Disse registrene sørger så for at alle nedstrømsapplikasjoner får høre om dette helt automatisk.
På den måten slipper vi å knote i de 40.000 datatabellene rundt om i hele NAV, så får vi mye gratis ved å ta i bruk forretningslogikk. En utfordring på prosjektet har vært å få alle systemene til å snakke godt sammen. Det finnes ikke en standardisert bruk av samme teknologi i systemene hos NAV. Løsningen på dette har vært å legge inn syntetiske testdata i de eksisterende systemene. Dette er et arbeid som fortsatt pågår.
NAV vant prisen for innebygd personvern
Datatilsynets delte ut prisen for “Innebygd personvern i praksis” våren 2020. Målet var å løfte frem gode eksempler på praktisk implementering av innebygd personvern og personvern som standardinnstilling. Gleden sto i taket da det ble kjent at det var NAV som vant med bidraget "Gjør test til en fest! Løsning og metode for syntetiske testdata". Løsningen og metoden som NAV har utviklet i samarbeid med twoday.
/Linda%20Hofstad%20Helleland.png?width=800&height=800&name=Linda%20Hofstad%20Helleland.png)